777me 谷歌AI芯片打平英伟达,最高配每秒42500000000000000000次运算

梦晨 发自 凹非寺量子位 | 公众号 QbitAI777me
谷歌首款AI推理特化版TPU芯片来了,专为深度念念考模子打造。

代号Ironwood,也即是TPU v7,FP8峰值算力4614TFlops,性能是2017年第二代TPU的3600倍,与2023年的第五代TPU比也有10倍。
(为什么诀别比第六代,咱也不知说念,咱也不敢问。)
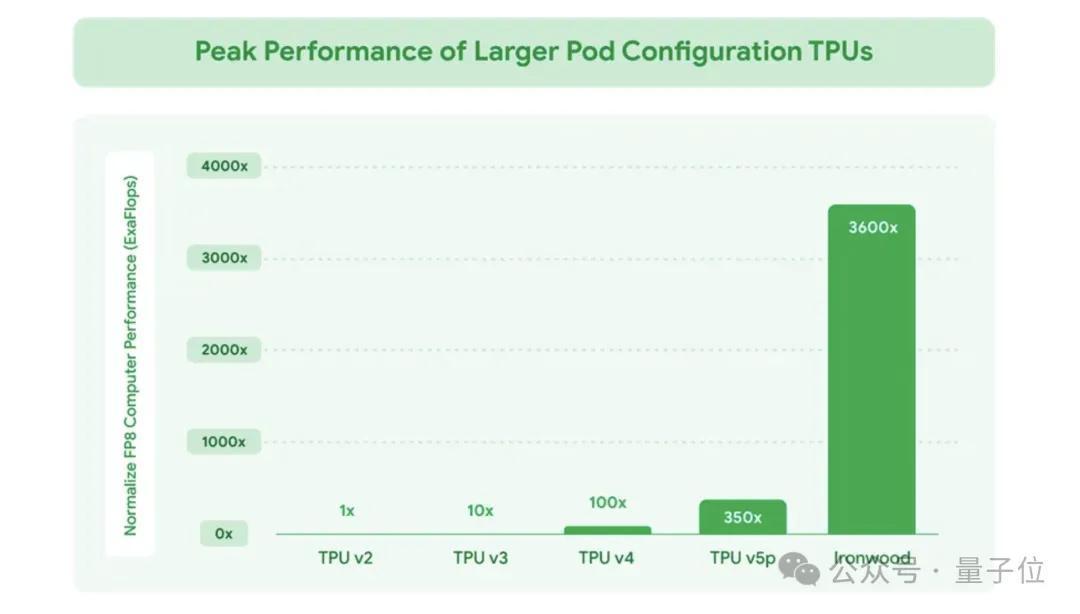
第七代TPU还隆起高推广性,最高配集群可领有9216个液冷芯片,峰值算力42.5 ExaFlops,也即是每秒运算42500000000000000000次。
是现在全球最强超等筹划机EL Capitan的24倍。
谷歌称,AI正从反应式(提供及时信息供东说念主类解读)滚动为粗略主动生成知悉息争读的滚动。
在推理时间,Agent将主动检索和生成数据,以相助的表情提供知悉和谜底,而不单是是数据。
汉典毕这小数,正需要同期空闲浩瀚的筹划和通讯需求的芯片,以及软硬协同的盘算推算。
谷歌AI芯片的软硬协同深度念念考的推理模子,以DeepSeek-R1和谷歌的Gemini Thinking为代表,现在王人是遴荐MoE(夹杂行家)架构。
固然激活参数目相对少,但总参数目浩瀚,这就需要大鸿沟并行解决和高效的内存看望,筹划需求远远超出了任何单个芯片的容量。
(o1大量推断亦然MoE,然而OpenAI他不open啊,是以莫得定论。)
谷歌TPU v7的盘算推算念念路,是在引申大鸿沟张量操作的同期最大截至地减少芯片上的数据挪动和蔓延。
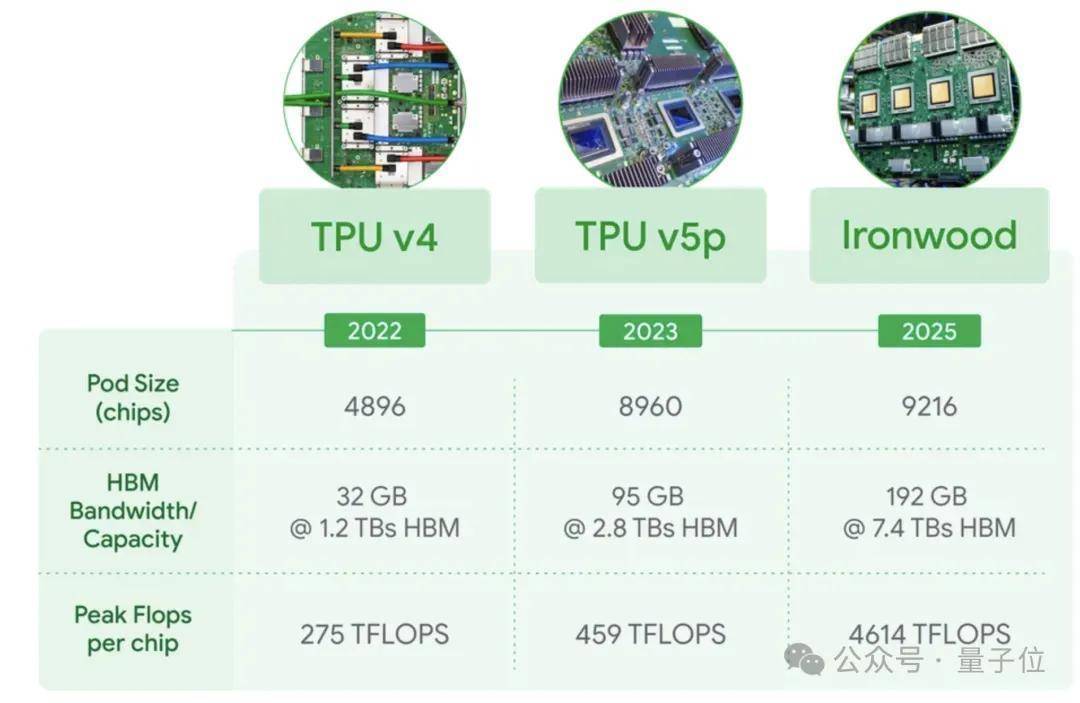
与上一代TPU v6比拟,TPU v7的高带宽内存 (HBM) 容量为192GB,是上一代的6倍,同期单芯片内存带宽普及到7.2 TBps,是上一代的4.5倍。
TPU v7系统还具有低蔓延、高带宽的ICI(芯片间通讯)网罗,复旧全集群鸿沟的和洽同步通讯。双向带宽普及至1.2 Tbps,是上一代的1.5倍。
能效方面,TPU v7每瓦性能亦然上一代的两倍。
硬件先容完,接下来看软硬协同部分。
TPU v7配备了增强版SparseCore ,这是一款用于解决高等排序和保举职责负载中常见的超大镶嵌的数据流解决器。
TPU v7还复旧Google DeepMind建树的机器学习启动时Pathways,粗略跨多个TPU芯片已毕高效的散布式筹划。
谷歌权谋在不久的改日把TPU v7整合到谷歌云AI超算,复旧复旧包括保举算法、Gemini模子以及AlphaFold在内的业务。
网友:英伟达压力山大了看过谷歌最新TPU发布,挑剔区网友纷繁at英伟达。
有东说念主称若是谷歌能以更低的价钱提供AI模子推理劳动,英伟达的利润将受到严重要挟。
还有东说念主平直at各路AI机器东说念主,运筹帷幄这款芯片对比英伟达B200如何。
浅易对比一下,TPU v7的FP8算力4614 TFlops,比B200标称的4.5 PFlops(=4500 TFlops)略高。内存带宽7.2TBps,比英伟达B200的8TBps稍低小数,是基本不错对看法两款产物。
黑丝在线实质上除了谷歌以外,还有两个云筹划大厂也在搞我方的推理芯片。
亚马逊的Trainium、Inferentia和Graviton芯片群众照旧比较纯熟了,微软的MAIA 100芯片也不错通过Azure云看望。
AI芯片的竞争,越来越强烈了。
参考贯穿:[1]https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/[2]https://x.com/sundarpichai/status/1910019271180394954777me